The Engineer as Orchestrator, Part III – The Practical Path to Modern Software Development
How engineering organizations operationalize AI-augmented development, build the tooling and processes, and deliver at scale.
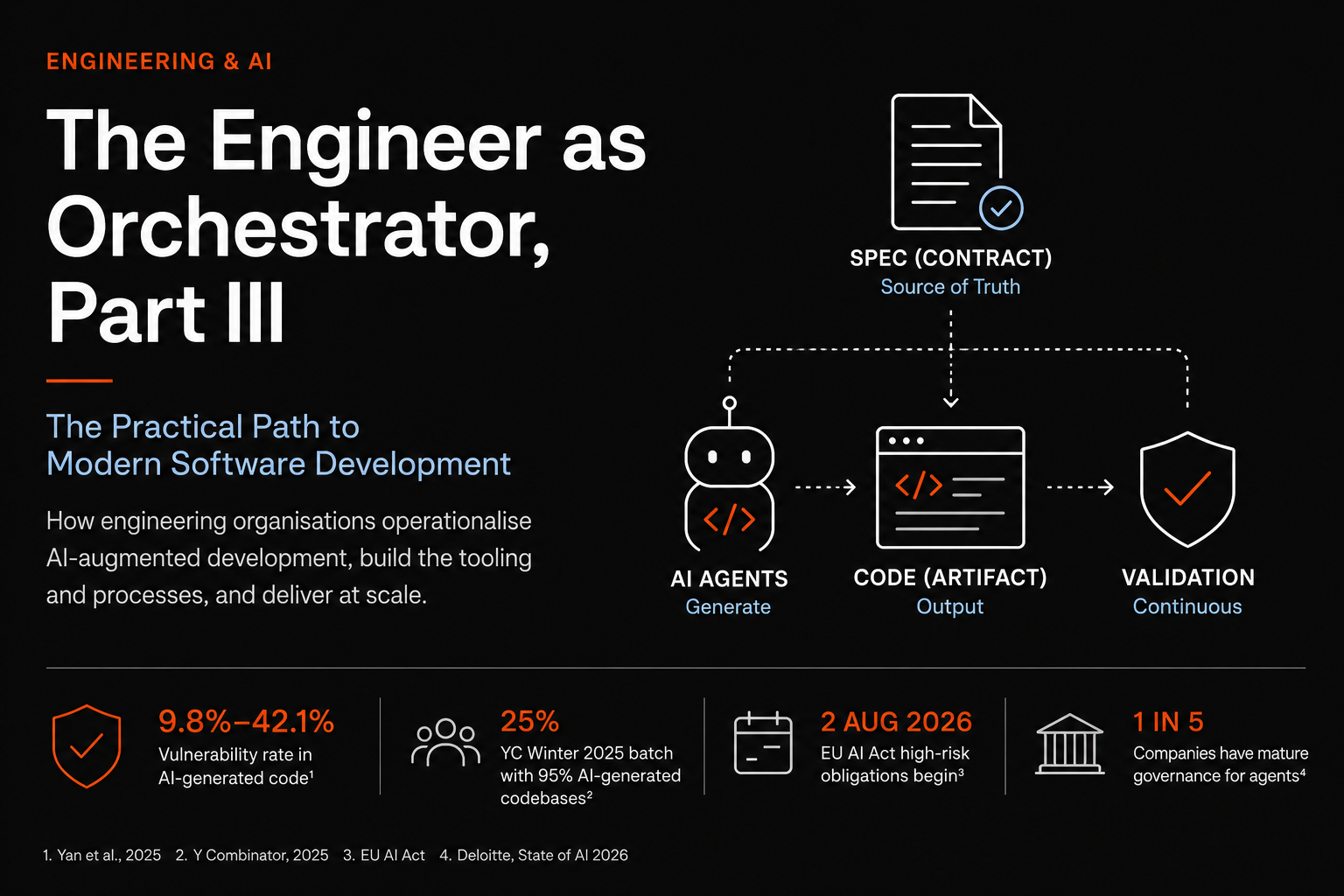
The first two parts of this series argued that the role of the engineer is shifting from author to orchestrator. This part is about what that actually looks like when an organization has to ship reliable software at scale, with AI agents producing the code and humans owning the outcome. The answer that has consolidated over the past eighteen months has a name, spec-driven development (SDD), and an ecosystem of frameworks worth understanding before you commit to one of them.
1. Why specs became the contract
1.1 The failure mode SDD was built to solve
The reason this approach exists is uncomfortable to say out loud. Large language models generate plausible code that drifts from intent, hallucinates APIs, and decays under any sustained scope. The most-cited empirical evidence remains Pearce et al. (IEEE S&P 2022), Asleep at the Keyboard? Assessing the Security of GitHub Copilot's Code Contributions, which generated 1,689 programs across 89 security-relevant scenarios and found approximately 40% contained exploitable vulnerabilities. The follow-on literature has not improved that picture materially. The February 2026 arXiv paper Spec-Driven Development: From Code to Contract in the Age of AI Coding Assistants framed the distinction that matters in one sentence: traditional specifications were written for humans to read, while spec-driven specifications execute as validation gates against the agent. The paper also introduces three levels of rigor (spec-first, spec-anchored, spec-as-source) that map cleanly to the frameworks in the next section.
1.2 The market and regulatory pressure
The market evidence is harder to argue with. Y Combinator partners reported in March 2025 that 25% of the Winter 2025 batch had codebases that were 95% AI-generated, a number Garry Tan repeated on his own feed. ThoughtWorks placed spec-driven development in the Assess ring of Technology Radar Volume 33 in November 2025, while also flagging in the same volume that overspecification is itself becoming an antipattern. DeepLearning.AI launched a dedicated short course, Spec-Driven Development with Coding Agents, built in partnership with JetBrains and taught by Paul Everitt. The EU AI Act starts enforcing high-risk obligations on August 2, 2026, with fines of up to €15 million or 3% of global turnover for non-compliance (Article 99 penalty schedule), which means audit trails on AI-generated code stop being optional for anyone selling into Europe.
1.3 What spec-driven development actually does
Structurally, SDD moves the source of truth one layer above the code. The specification describes what the system is supposed to do in a format both humans and agents can read, the agents generate code against that specification, and the specification stays alive as requirements evolve. Whether code remains the maintained artifact (the pragmatic view) or eventually becomes a byproduct of the spec (the radical view) is a genuine industry debate. Martin Fowler's practitioner overview and the ThoughtWorks Medium piece on SDD are the two best starting points for understanding why reasonable people land in different places on that spectrum.
The common building block across frameworks is EARS notation (Easy Approach to Requirements Syntax), originally devised by Alistair Mavin and colleagues at Rolls-Royce in RE'09. Its five sentence patterns (Ubiquitous, Event-driven, State-driven, Unwanted-behaviour, Optional-feature) produce statements unambiguous enough for both humans and models to verify against, which is why almost every modern SDD framework adopted it. The Wikipedia page is a fast reference for the syntax itself.
2. The framework landscape
The tooling between mid-2025 and now has gone from one or two experiments to more than thirty named frameworks, and the result is fragmented but legible. Five projects cover most of what teams are actually using in production.
2.1 At a glance
Framework | Best for | Weight | Repo / link |
GitHub Spec Kit | Greenfield features, multi-agent portability | Heavy | |
OpenSpec | Brownfield iteration, change approval gates | Light | |
BMAD-METHOD | Cross-discipline work, simulated agile teams | Heaviest | |
AWS Kiro | AWS-native teams wanting an IDE-integrated workflow | Medium | |
Tessl | Experimental spec-as-source | Radical |
2.2 GitHub Spec Kit
github/spec-kit is the reference implementation and the one most teams encounter first. It is a Python CLI plus a set of templates and slash commands that work with 30 plus AI coding agents including Claude Code, Copilot, Cursor, Codex CLI, Gemini CLI, and Qwen Code. The workflow runs through /speckit.constitution, /speckit.specify, /speckit.clarify, /speckit.plan, /speckit.tasks, /speckit.analyze, and /speckit.implement (the full Quick Start guide walks through the sequence). The repo had reached roughly 88,000 stars by April 2026, and Microsoft's developer blog ran an early walkthrough on how the toolkit handles bootstrap and template management. Both Bash and PowerShell variants of the automation scripts ship by default, which matters more than it sounds in mixed Windows and Linux enterprise environments. Spec Kit is greenfield-friendly and heavyweight, and the planning investment pays off on medium-to-large features where rework is expensive.
Use it when: you are building new capabilities, your team uses several different coding agents, and you want a workflow that survives switching between them.
2.3 OpenSpec
Fission-AI/OpenSpec takes a deliberately lighter approach and targets the brownfield case that Spec Kit handles poorly. Its core concepts separate openspec/specs/ as the source of truth from openspec/changes/ as proposed deltas, with each change folder containing a proposal, design notes, tasks, and spec deltas marked ADDED, MODIFIED, or REMOVED relative to existing functionality. Output runs around 250 lines per change versus roughly 800 for Spec Kit, which cuts review overhead substantially. The project site at openspec.dev frames its philosophy as fluid not rigid, iterative not waterfall, easy not complex, and brownfield-first. The trade-off is that specs do not self-update during implementation, so if an agent changes its approach mid-task the proposal document does not reflect that automatically. Daniel Bryant's intent-driven.dev knowledge base is the most thorough secondary source for OpenSpec patterns in production.
Use it when: you are iterating on a mature codebase, every change needs a reviewable approval gate, and you want minimal ceremony.
2.4 BMAD-METHOD
bmad-code-org/BMAD-METHOD is the heaviest of the open-source options and the closest analogue to running a real software development team. Version 6.6.0 shipped on April 29, 2026, with the project at 46,700 stars and over 5,500 forks. It orchestrates twelve plus specialised agents across the full SDLC, each with a defined role (Business Analyst, Product Manager, Architect, Product Owner, Scrum Master, Developer, QA, and others), explicit context access, and file-based handoffs where each agent reads the previous agent's output document and writes its own.
The V6 architecture splits responsibilities across three layers:
BMad Core:
the universal human-AI collaboration framework
BMad Method:
the agile development module built on Core
BMad Builder:
the toolkit for building your own modules on top
The Cross Platform Agent Team allows the same agent configuration to run across Claude Code, Cursor, Codex, and other hosts without reconfiguration. Mathivanan Mani's comparative analysis on Medium is a useful side-by-side of BMAD against Spec Kit and OpenSpec on real brownfield work.
Use it when: the work crosses multiple disciplines (PM, architecture, dev, QA) and the handoffs between them are where things actually break.
2.5 AWS Kiro
Kiro is the IDE-native approach. It is a VS Code fork with the spec lifecycle (Constitution, Specify, Plan, Tasks, Implement, PR) built directly into the workspace, and it integrates deeply with AWS. The cost is vendor lock-in to both AWS and the bundled Claude models. AWS marketing has documented customer cases where features that would have taken 40 hours of human time shipped in under 8 when authored as specs first, though those numbers come from AWS and should be treated accordingly. The definitive 2026 SDD guide on BCMS gives a balanced read of where Kiro currently fits relative to the open-source alternatives.
Use it when: you are already committed to AWS and want spec-driven workflows without assembling the toolchain yourself.
2.6 Tessl
Tessl is the most radical position on this map and the least production-ready. Its framework treats specs as the primary maintained artifact, with code generated and marked at the top with comments like // GENERATED FROM SPEC - DO NOT EDIT. The current 1:1 mapping between spec file and code file echoes model-driven development from the 2000s, which never broke through because the abstraction overhead exceeded the productivity gain. Tessl is betting that LLMs eliminate enough of that overhead to make spec-as-source viable, and whether they are right is genuinely open. The company raised $125 million across seed and Series A at a $500M plus post-money valuation, with Index Ventures leading the Series A and participation from Accel, GV, and boldstart. Founder Guy Podjarny previously built Snyk to a $7.4bn valuation, so the bet is well-capitalised even if the thesis is unproven.
Use it when: you have an experimental project where you actively want to test the spec-as-source thesis, or you are designing the next generation of internal tooling.
2.7 Honourable mentions
GSD (
get-shit-done-cc):crossed 61,000 GitHub stars in five months as a lean Claude Code-native alternative to BMAD, with multi-agent orchestration that spawns parallel researchers and verifiers in fresh context windows. Background in the
CLAUDE.md / AGENTS.md:
the lightest possible version of SDD. A markdown context file the agent reads on every session. Structurally it does the same job as a formal framework with less ceremony. If you are already maintaining a detailed CLAUDE.md, you are already running a lightweight version of this, which is the most important framing point in the whole conversation. The frameworks formalise something a lot of teams already do informally. Alex Cloudstar has a thoughtful comparison piece that argues this position more strongly than most.
3. What we learned building SANDF
We built SANDF (Systematic AI Native Development Framework) before this ecosystem fully consolidated, which means we made some of the same architectural decisions independently and got some of them wrong. The bones look familiar if you have used Spec Kit or BMAD. We separate work into phases (Discovery and Research at Phase 0, Product Definition at Phase 1, then architecture, spec generation, implementation, and review), with formal gates between them. Gate 1 sits at PRD approval, Gate 2 at TDD approval. Each phase has its own skill (a markdown file the agent reads to understand its role and constraints) and produces specific artifacts that the next phase consumes.
3.1 What worked: phase isolation beats phase granularity
The things every successful SDD framework eventually converges on are not about adding more steps. What kills these systems is leakage between phases, not the number of phases. Forcing the agent to write the PRD before any architectural decision is made, and the TDD before any code is written, removes the failure mode where the agent justifies a technical choice by retrofitting the requirement to fit it. EARS notation for acceptance criteria gives us statements that are unambiguous enough for both humans and agents to verify against, which is the same reason every other framework adopted it.
3.2 What we got wrong: too many gates
Our first version had a gate at every artifact approval, and the friction of moving between them dominated the actual work. We collapsed it to two formal gates and made the rest advisory checkpoints, which roughly halved the time to first working code without measurably affecting defect rates. The lesson generalizes: every approval gate costs real time, and most of them do not earn their keep. This is the same concern ThoughtWorks raised in Volume 33 about SDD reverting to waterfall when overdone.
3.3 What we got wrong: specs drift no matter what
Our second mistake was assuming the spec would stay in sync with the code if we wrote the rules clearly enough. It does not. Specifications drift during implementation regardless of what the framework says, and the only fix is a reconciliation step at PR time that compares the implementation against the spec and flags differences for human review. This is the same problem pushing Intent and Tessl toward bidirectional living specs, and we ended up at a less ambitious version of the same answer.
3.4 What we got wrong: not every task earns a spec
The framework only justifies itself in environments where the audit trail genuinely matters. For small fixes or exploratory work, the overhead of producing a PRD, TDD, and engineering spec for a one-line change costs more than the time saved by structured execution. We added a fast path for changes under a defined complexity threshold (loosely, anything that touches fewer than three files and has no architectural implication) where the agent goes straight to implementation against an existing spec. That matches the practical advice that has emerged from the Spec Kit community: the trigger for writing a detailed spec is whether you would be annoyed if the agent interpreted the requirement differently than you meant.
3.5 The lesson we did not expect: product becomes the bottleneck
Once you have a working SDD pipeline, the constraint moves upstream. The agents are faster than the PRDs feeding them, and "we don't have a clear spec" becomes the default reason features are delayed, where previously it would have been "engineering is overloaded." This is uncomfortable for product organizations that historically treated requirements as a starting suggestion rather than a contract, and it is the change that takes longest to absorb culturally.
4. Operationalizing this in your organization
4.1 The five questions you need to answer
There is no shortcut that lets you adopt one of these frameworks and skip the work of integrating it into how your engineering organization actually delivers software. The decisions that matter are the same ones that matter for any process change:
Where does the spec live?
In the repository, alongside the code it governs, or it ends up stale.
Who owns it when requirements change?
The team shipping the feature, not a separate spec author.
How does it interact with existing review processes?
It has to replace some of them, or it just adds overhead.
How are agents constrained to follow it?
Constitution files, slash commands, and gate enforcement at PR time.
What happens when the spec and the code disagree?
You need a documented reconciliation step or the spec dies within weeks.
4.2 Choosing a starting framework
The honest answer about which framework to start with is that it depends on the shape of your codebase:
Greenfield work
fits Spec Kit.
Brownfield iteration
fits OpenSpec.
Multi-discipline work
with formal stakeholder handoffs fits BMAD.
AWS-native teams
fit Kiro.
None of these is a wrong choice, and several teams I know are running two of them in parallel for different parts of their work, which is uglier than picking one but pragmatic.
4.3 The deeper point
The mistake is treating any of these tools as a methodology. The methodology is older than the tools and survives them. It comes down to writing down what you are building and why before you build it, agreeing on it with the people who care, giving it to the agent as the contract, and verifying the output against the contract rather than against your memory of the conversation that produced it.
The shift this represents for engineering organisations is real but not as dramatic as the vendor messaging suggests. The work of writing good specifications is the same work product managers and senior engineers have always done in the parts of the lifecycle where they did it well. The frameworks make that work portable, executable, and auditable, which is what changes when you put an agent on the other side of it. The engineers who adapt to this are the ones who already wrote things down before writing code. The ones who struggle are the ones who treated documentation as a tax. The agent does not change which of those was the right approach.
References and further reading
Foundational research
Pearce, H., Ahmad, B., Tan, B., Dolan-Gavitt, B., & Karri, R. (2022).
Asleep at the Keyboard? Assessing the Security of GitHub Copilot's Code Contributions.
IEEE Symposium on Security and Privacy.
Spec-Driven Development: From Code to Contract in the Age of AI Coding Assistants
(February 2026).
Mavin, A., Wilkinson, P., Harwood, A., & Novak, M. (2009).
Easy Approach to Requirements Syntax (EARS).
IEEE RE'09. Reference site:
Industry signals and analysis
ThoughtWorks Technology Radar Volume 33 (November 2025):
ThoughtWorks blog:
Spec-driven development. Unpacking one of 2025's key new practices
Martin Fowler:
Understanding Spec-Driven Development: Kiro, spec-kit, and Tessl
BCMS:
TechCrunch:
A quarter of YC's current cohort have codebases that are almost entirely AI-generated
MarkTechPost:
Frameworks and repos
GitHub Spec Kit: github.com/github/spec-kit , Quick Start
OpenSpec: github.com/Fission-AI/OpenSpec , openspec.dev
BMAD-METHOD: github.com/bmad-code-org/BMAD-METHOD
AWS Kiro: kiro.dev
Regulatory
EU AI Act overview:
EU AI Act Article 99 (penalties):
Learning
DeepLearning.AI x JetBrains:
Spec-Driven Development with Coding Agents (Paul Everitt)
Course companion repo:
Practitioner blogs worth following
intent-driven.dev (OpenSpec and brownfield SDD patterns)
Daniel Bryant on InfoQ: Enterprise Spec-Driven Development (search "Bryant spec-driven")
Jehad Alkhateeb
AI & Digital Experience Architect with 11+ years of experience building intelligent systems and leading engineering teams. Based in Toronto, Canada.
Related Articles
The Engineer as Orchestrator, Part II The Mindset Shift
Why the future of engineering leadership depends on intent, context, and collaboration between humans and intelligent systems.
The Future of Software Engineering, Part I: From Builder to Orchestrator
Why AI coding agents mark a deeper shift in how we design, deliver, and define software itself.